-
1. Basic introduction of statistical learningMachine Learning Explained 2021. 1. 19. 16:52
Basic of statistical Learning
X_1, X_2, ... , X_p가 주어졌을 때 Y를 구하는 것 (prediction)
X_1, X_2, ... , X_p와 Y의 관계를 이해하고 X가 달라짐에 따라서 어떻게 Y가 달라지는지 이해하는 것 (inference)
- Y = f(X) + ε
- X; 독립변수 = 설명변수 = Input variables = predictors, independent variables, features, variables
- Y; 종속변수 = 반응변수 = Output variables = response, dependent variable
- ε; 오차항 = random error term = independent of X and has mean zero (normally distributed around mean zero)
1. Prediction 예측
앞서 말한 오차항의 평균이 0이기 때문에 y를 predict 하면 다음과 같은 결과가 나온다:
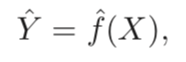
ŷ는 y를 예상한 값이고 다음과 같이 2가지 오차에 따라 그 정확도를 측정할 수 있다:
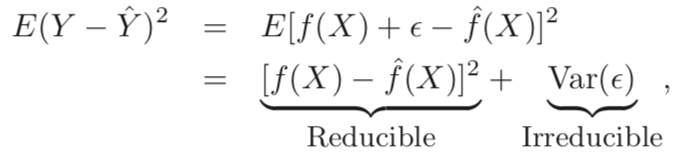
- a) reducible error: 말 그대로 reducible 한 error이다. f^은 f의 값을 예측한 것이기 때문에 오차가 발생할 수 밖에 없다. 이러한 오차는 알맞은 statistical learning technique를 사용함으로써 줄일 수 있다.
- b) irreducible error: 줄이지 못하는 오차이다. 앞서 말한 바와 같이 Y = f(X) + ε 이고 여기서 오차항인 ε 는 "independent of X" 하다. 즉, 우리는 ε 를 주어진 X를 가지고 예측할 수 없기 때문에 얼마나 f를 잘 예측하는지 상관없이 ε 에서 나오는 오차는 줄일 수 없다.
- irreducible error가 0보다 큰 이유 (항상 존재하는 이유):
- Y를 구하는데 있어서 필요하지만 쓰이지 않은 X가 있을 수 있다.
- unmeasurable한 variation을 포함할 수 잇다.
- irreducible error가 0보다 큰 이유 (항상 존재하는 이유):
- E(Y − Yˆ )^2: average = expected value = squared difference between predicted and actual value of Y
- Var(ε): variance associated with error term 오차항의 분산
- 목표:
- estimate f
- minimize reducible error
2. Inference 추론
- X 와 Y의 관계를 이해하는것
다음과 같은 질문을 할 수 있다:
- Which predictors are associated with the response? (identifying the important predictors)
- What is the relationship between the response and each predictor?
- Can the relationship between Y and each predictor be adequately summarized using a linear equation, or is the relationship more complicated than that?
3. When to use prediction ? vs. When to use inference?
알아내고자 하는 것에 따라서 예측을 쓸 수 있고 추론을 쓸 수 있다.
1. 예측을 쓸 경우:
- 목표: 마케팅 캠페인 이메일에 긍정적으로 답할 사람들을 찾아내기
- Y: 마케팅 캠페인에 대한 반응 (긍정적/부정적)
- X: demographic variables
2. 추론을 쓸 경우:
- TV, PV/Mobile, Radio 각각의 광고 효과의 데이터가 있다고 치자. 광고의 효과를 측정하는 지표는 sales로 정했을 경우, 다음과 같은 질문들을 통하여 추론이 가능하다:
- 어떤 미디어가 가장 많이 sales에 contribute 했을까?
- 주어진 TV의 광고의 증가에 따른 sales의 변동은 어떻게 될까?
4. Parametric vs. Non-parametric methods
Statistical Learning method은 크게 2가지로 나누어 진다:
1. Parametric
2. Non-parametric
자세한 내용을 다루어 보자.
1. Parametric:
- 정의: model-based approach이다. 즉, 모델을 정하고 나서 알맞은 파라미터 값을 구하는 것이다.
- 방법: 2-step
- f의 functional form/shape에 관한 가정을 한다. 예를 들어, "f is linear in X"라는 가정을 세우면 다음과 같은 식으로 나타낼 수 있다: f(X) = b_0 + b_1 X_1 + b_2 X_2 + ... + b_p X_p
- training 데이터를 사용하여 모델을 train 한다. 예를 들어, 앞서 언급한 선형회귀에 데이터를 fit하기 위하여 Ordinary least squares를 사용 할 수 있다.
- 장점: f 전체를 예측하는 것이 아니라 파라미터 셋을 예측하는 문제가 되어서 더욱 간단하다.
- 단점: 모델에 대한 가정을 하기 때문에 true unknown form of f를 예측하는 것은 힘들다. 이에 대한 대책으로는 flexible한 모델을 ㅆ는 것인데 보통 parameter 수를 늘리고는 한다. 하지만 파라미터 수를 늘려서 더욱 복잡한 모델을 만들게 되면 데이터를 overfitting하는 위험이 있다.
2. Non-parametric methods
- 정의: f 의 functional form 에 대한 가정을 하지 않고 각 데이터 포인트에 가장 가까운 f 를 추측한다.
- 장점: 가정을 세우지 않기 때문에 다양한 shape를 시도할 수 있고 따라서 정확도 또한 parametric method보다 높다.
- 단점: f 자체를 예측하지 않고 적은 수의 파라미터를 예측하는 것이 불가하기 때문에 parametric approach에서 쓰인 파라미터 갯수보다 월등히 많은 파라미터가 필요하다. 따라서 오버피팅의 위험이 있다.
5. Trade-Off between Prediction Accuracy and Model Interpretability
일반적으로 flexibility가 증가할수록 interpretability는 줄어든다.
- Inference(추론)을 할 경우에는 flexibility를 높여서 정확도를 높이는 것보다 interpretability에 맞추어 변수들 간의 관계를 알아내는 것이 더 적합하다. 반면,
- prediction(예측)을 할 경우에는 정확도가 중요하기 때문에 interpretability는 신경을 쓸 필요가 없다. 하지만 그렇다고 하여 꼭 more flexible한 method이 더 정확한 결과를 도출하지는 않는다. 오버피팅의 문제 때문이다.
[Figure1] 을 보자:
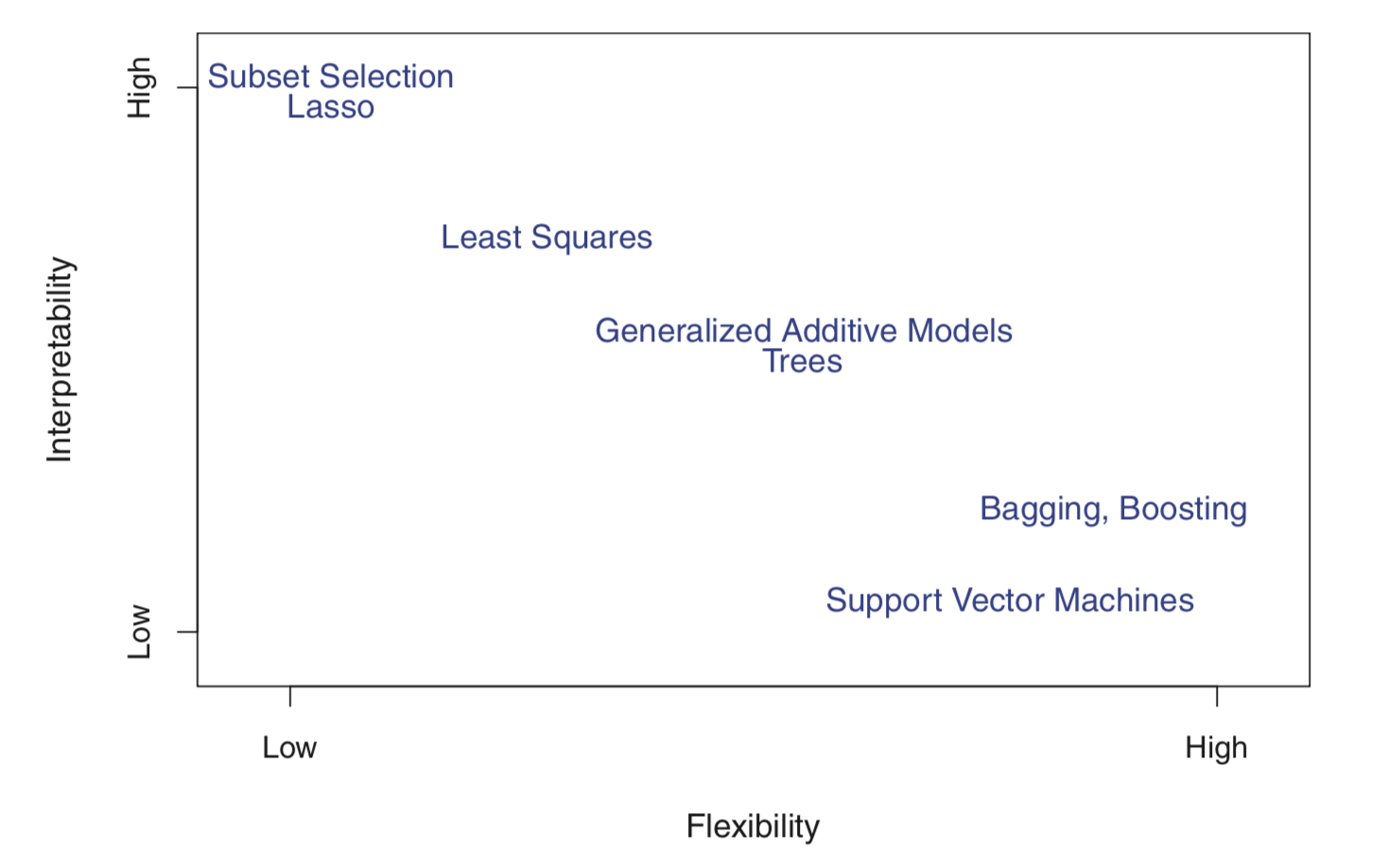
[Figure 1]: Tradeoff between Flexibility and Interpretability - Least squares has relatively low flexibility & relatively high interpretability
- Lasso has lowest felxibility & highest interpretability. 그 이유는 lasso는 linear model에 추가적인 fitting procedure를 더하는데 그 결과 계수를 예측하는데 있어서 linear model보다 더 제한적이다. 자세히 말하자면 shrinkage method을 쓰는데 ridge와 다르게 lasso의 경우 중요하지 않은 변수의 계수를 0으로 만들어 준다.
- Generalized Additive Models (GAMs) 는 linear model에 특정한 non-linear relationship을 더한 것으로 linear regression보다 flexible하다. 다만, 독립변수와 종속변수의 관계를 선이 아닌 곡선으로 표현하는 것이기 때문에 less interpretable하다.
- bagging, boosting, support vector machine with non-linear kernals와 같이 fully non-linear methods는 매우 flexible하지만 interpret하기 어렵다.
6. Supervised vs. Unsupervised Learning
- Supervised Learning: 독립변수와 종속변수가 존재함
- Prediction, Inference
- logistic regression, GAM, boosting, SVM, etc
- Unsupervised Learning: 독립변수만 존재함
- Clustering
'Machine Learning Explained' 카테고리의 다른 글
0. An Introduction to statistical learning (0) 2021.01.19