-
Empirical Asset Pricing using Machine LearningProject 2021. 1. 4. 18:18
1. Empirical Asset Pricing 이란?
- Asset pricing의 경우 CAPM/Fama-French 등 다양한 가격결정 모형을 사용하는 것.
- Empirical Asset pricing은 다양한 데이터를 수집하여 자산 가격을 결정하는 것.
2. Asset Pricing에 Machine Learning을 쓰는 이유
1) Risk premium = Expected return - Risk Free Rate
- 머신러닝은 예측에 매우 전문화되어 있다. 따라서 리스크 프리미엄 측정 문제에 잘 사용될 수 있다.
2) 자산가격을 예측하는 데 사용되는 변수의 종류들은 다양하다. 여러 가지 stock level characteristics 뿐만 아니라 macroeconomic predictors도 포함된다. 변수들이 서로 높은 상관관계를 보일 때도 있는데 머신러닝을 사용할 경우 dimensionality redcution을 통하여 유용한 변수들을 추려낼 수 있다.
3) 기존 방식과 달리 머신러닝은 functional form에 관한 flexibility를 제공한다. 예를 들어 linear model을 쓸 것인지 non-linear 한 모델을 쓸 것인지 여러 모델을 적용할 수 있다. 변수들 사이의 복잡한 관계를 approximate 할 수 있으며 parameter penalizing과 model selection을 통해 오버 피팅과 잘못된 모델 사용을 방지할 수 있다.
3. Data Collection & Preprocessing
다음과 같은 데이터를 사용하였다:
1) Target variable : r_i, t (S&P 500 index의 monthly return)
Yahoo Finance에서 데이터를 수집하였는데 아래와 같은 데이터를 수집하게 된다.

내가 원하는 것은 monthly return이기 때문에 계산해준다:
Market return = Stock return - Risk free rate
Stock return = (end-start)/start

2) Dependent variable
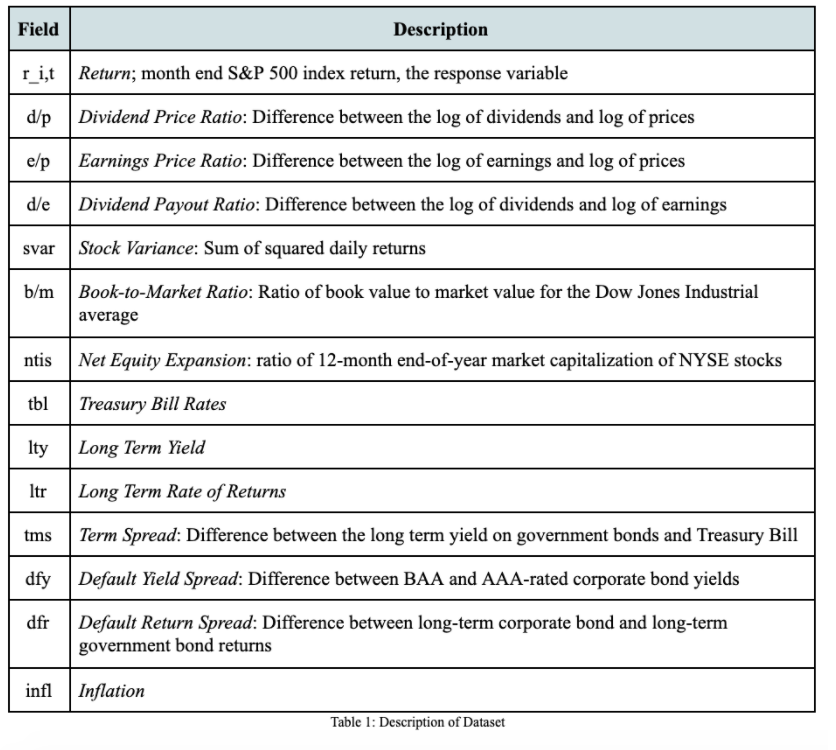
위에 있는 표1에서 r_i, t를 제외한 전부가 다 종속변수로 쓰였다. 각 변수에 대한 설명은 표에 있으니 참조하면 된다.
데이터는 Amit Goyal의 웹사이트에서 수집하였다. 종속변수를 크게 2가지로 나누었다:
1. primary stock characteristics: d/p, e/p, d/e, svar, b/m, ntis
2. interest rate related characteristics: tbl, lty, ltr, tms, dfy, df, infl
3) Data preprocessing
Training Dataset
1938.01 - 1999.12Testing Dataset
2000.01 - 2019.12데이터를 testing과 training 셋으로 나눈다. 또한 Date 컬럼을 변수에서 제거했다.

Data Scaling을 진행한다. 머신러닝을 진행하면 데이터를 그대로 받아들이기 때문에 변수들 의 데이터 range가 다른 경우 scaling을 해주는 것이 좋다. sklean 라이브러리에 있는 preprocessing.StandardScaler()를 사용하였다. StandardScaler()는 데이터가 mean 0, standard deviation 1으로 normally distributed 하다고 가정한다.

4. Exploratory Data Analysis

correlation heatmap Pandas Profiling을 사용하여 상관관계 히트맵 시각화를 진행하였다. correlation r의 절댓값이 0.7보다 큰 경우, 상관관계가 높다고 할 수 있다. 히트맵을 보면 높은 상관관계를 가진 변수들은 다음과 같다:
- lty(long term rate of return) & tbl(treasury bill rate)
- b/m (book to market ratio) & d/p (dividen price ratio)
Target variable인 r_i,t와 나머지 변수들의 상관관계를 보면 significant 한 관계는 보이지 않는다.
5. Results
1) OLS
OLS는 ordinary least squares regression으로 회귀에서 가장 기본적으로 사용되는 모델이다. sum of sqaured residuals를 최소화시키는 방법을 쓴다.

sklearn의 linearmodel.LinearRegression()을 사용하였다.
MSE는 0.00258로 적은 편이다.
여러 가지 변수들 중에 어떤 변수의 featrue importance이 높은지 알아보자.
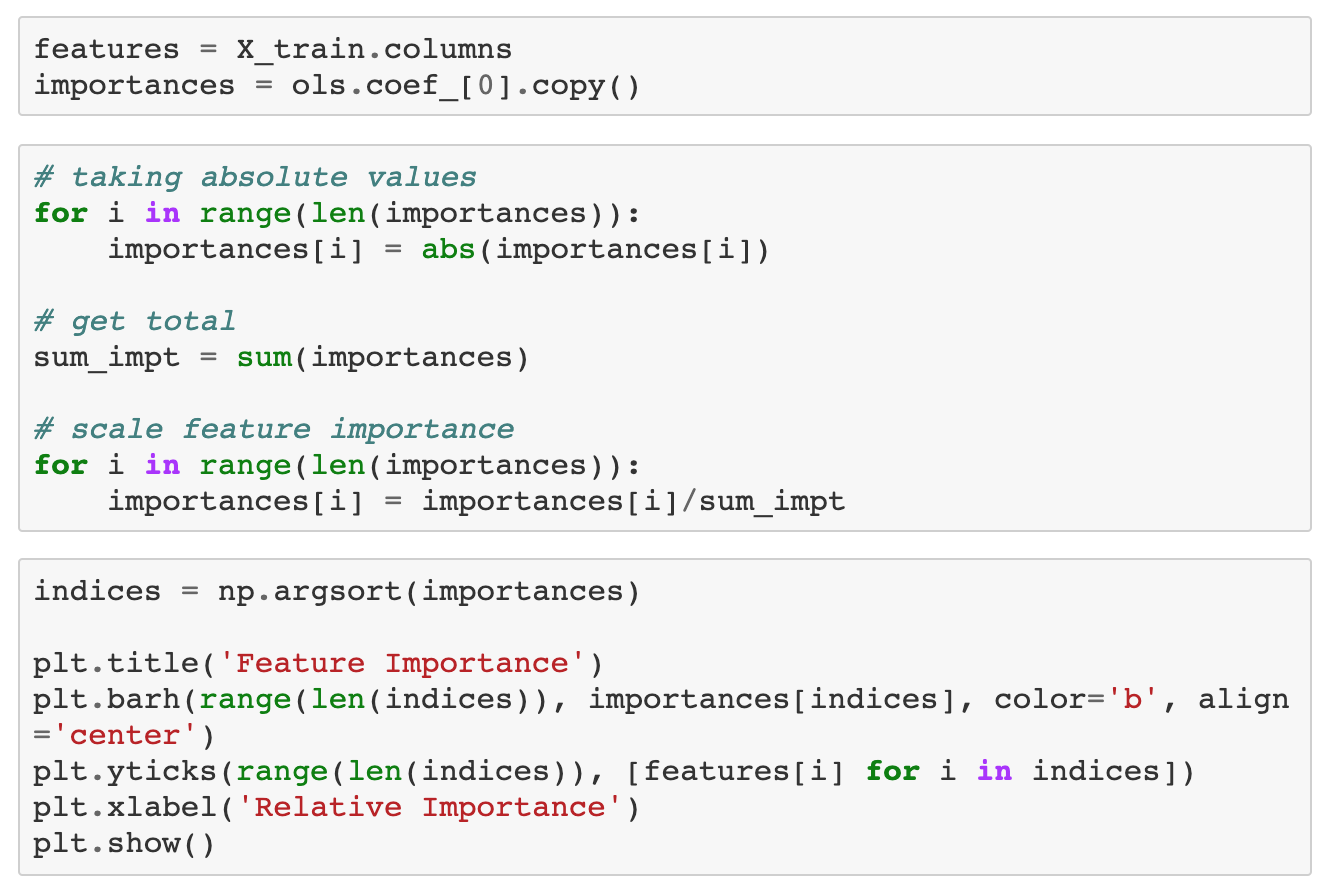

결과를 보면 feature importance가 0.05보다 높은 변수들은 d/p, e/p, d/e가 있다.
2) Ridge Regression
sklearn.linear_model.RidgeCV를 사용하였다. Ridge regression은 정규화된 linear regression model로 ridge estimator를 모델에 사용함으로써 multicollinearity를 해결할 수 있다. 교차검증 방법으로는 Leave One Out Cross Validation(LOOCV)을 사용하여 튜닝 파라미터를 찾았다. 21.6438을 튜닝 파라미터로 썼고 최종 MSE는 0.002337이 나왔다.

Feature importance를 살펴보면 significant 한 feature는 tbl, lty, ltr, svar, dfr, dfy, tms이다.
3) Lasso
Lasso는 Ridge처럼 linear regression에 페널티를 부과한다. 다른 점이라면 Lasso는 상관이 없는 변수들의 값을 0으로 만들 수 있기 때문에 영향이 적은 변수들을 배제할 수 있게 해 준다.
교차검증에는 5-fold cross validation을 사용하였고 그 결과 튜닝 파라미터의 값은 0.00131로 나왔다. 튜닝 파라미터를 적용하여 분석을 한 결과 MSE는 0.00129로 나왔다.


significant 한 변수들은 다음과 같다: tbl, ltr, svar, dfr
4) Random Forest
sklearn.ensemble.RandomForestRegressor를 사용하여 머신러닝을 진행하였다. 알맞은 파라미터 설정을 위하여 3-fold cross validation으로 n_estimator, max_features, max_depth, min_samples_split, min_samples_leaf, bootstrap 값을 설정하였다.
그 결과 다음과 같은 결과값이 나왔다:

위에의 결과값을 RandomForestRegressor에 입력해준다.

MSE의 결과값은 다음과 같다:

RandomForestRegressor에는 feature_importances_가 있어서 쉽게 feature importance를 구할 수 있다. Significant feature는 tbl, svar, ltr, dfr, dp로 나왔다.
sorted(RF.feature_importances_, reverse=True) 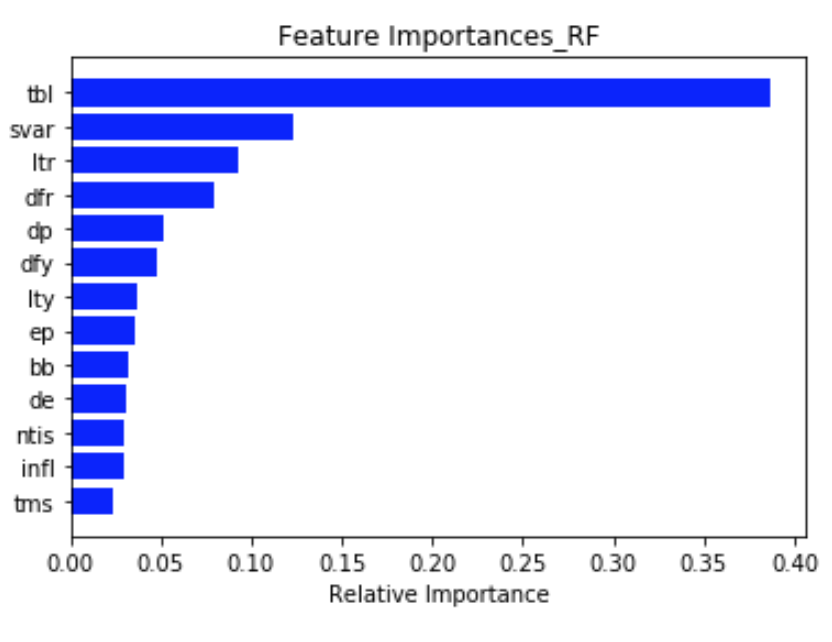
5) Support Vector Regression (SVR)
10-fold cross validation을 통해 튜닝 파마리터를 정했고 그 결과, MSE는 0.002984가 나왔다. Significant features는 ltr, tbl, svar, lty, dfr, dfy, tms, infl, ntis이다.



6) Gradient Boosted Regression Tree (GBRT)
3-fold cross validation으로 파라미터 값을 설정하였고 그 결과 MSE는 0.001864가 나왔다.
다음과 같은 파라미터를 교차검증으로 설정하였다:

결과값은 다음과 같다:

결과값을 입력하여 얻은 MSE:
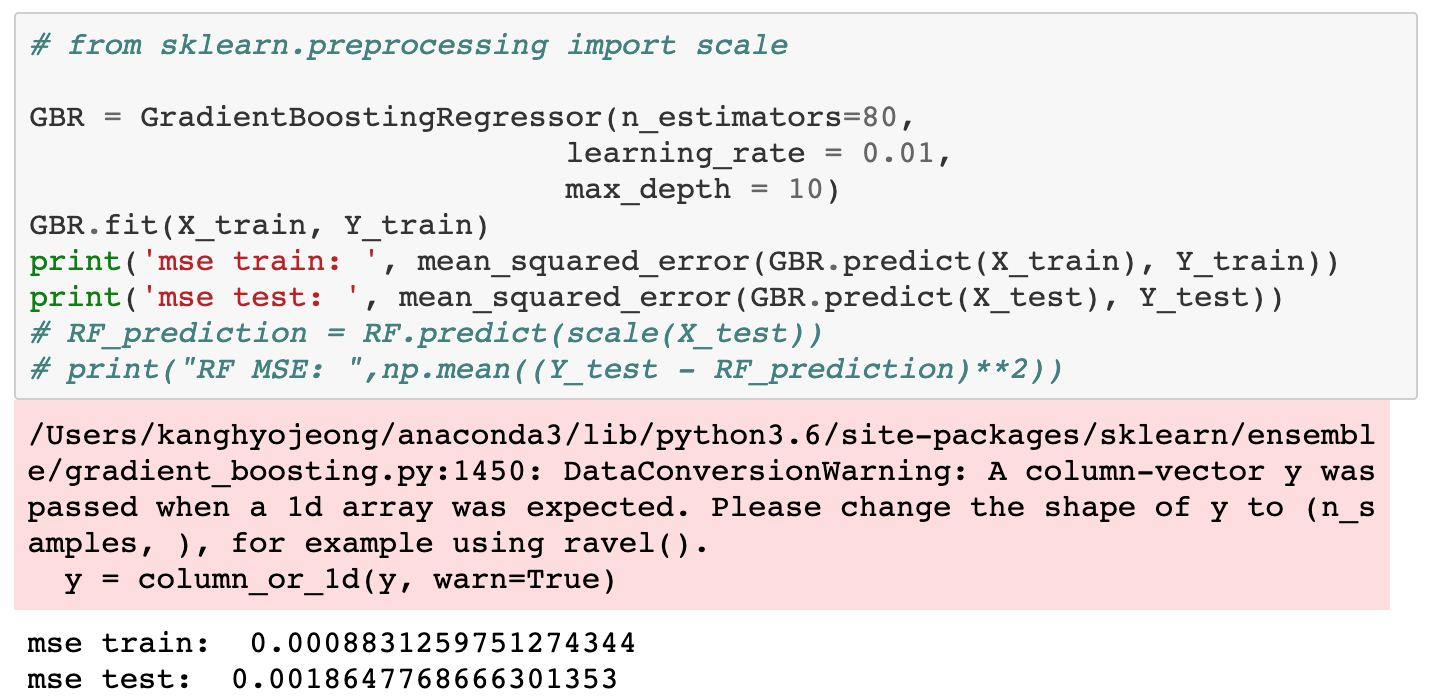
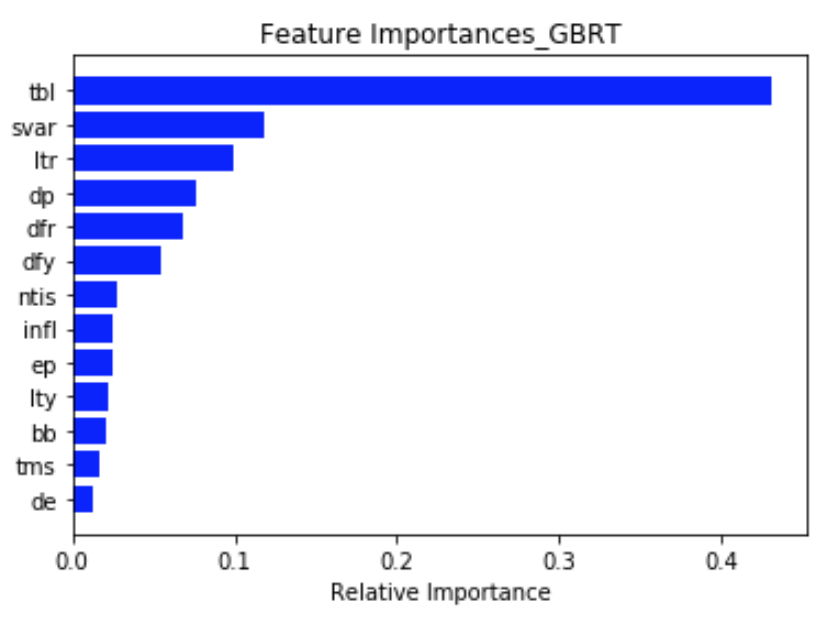
Feature importance에서 significant한 값은 tbl, svar, ltr, dp, dfr, dfy이다.
7) Long Short Term Memory (LSTM)
LSTM은 RNN의 한 종류로써, RNN의 vanishing error problem을 해결할 수 있다. Vanishing error problem을 간단하게 설명하자면, 과거의 input들의 영향이 시간이 지남에 따라 줄어든다는 것인데, 이러한 RNN의 문제점을 LSTM은 memroy cell을 사용하여 해결한다.
LSTM에 5 hidden layers을 사용하였고 geomatric pyramid rule에 따라서 각 층의 뉴론 개수를 설정하였다. 아키텍쳐의 자세한 구성은 다음과 같다:
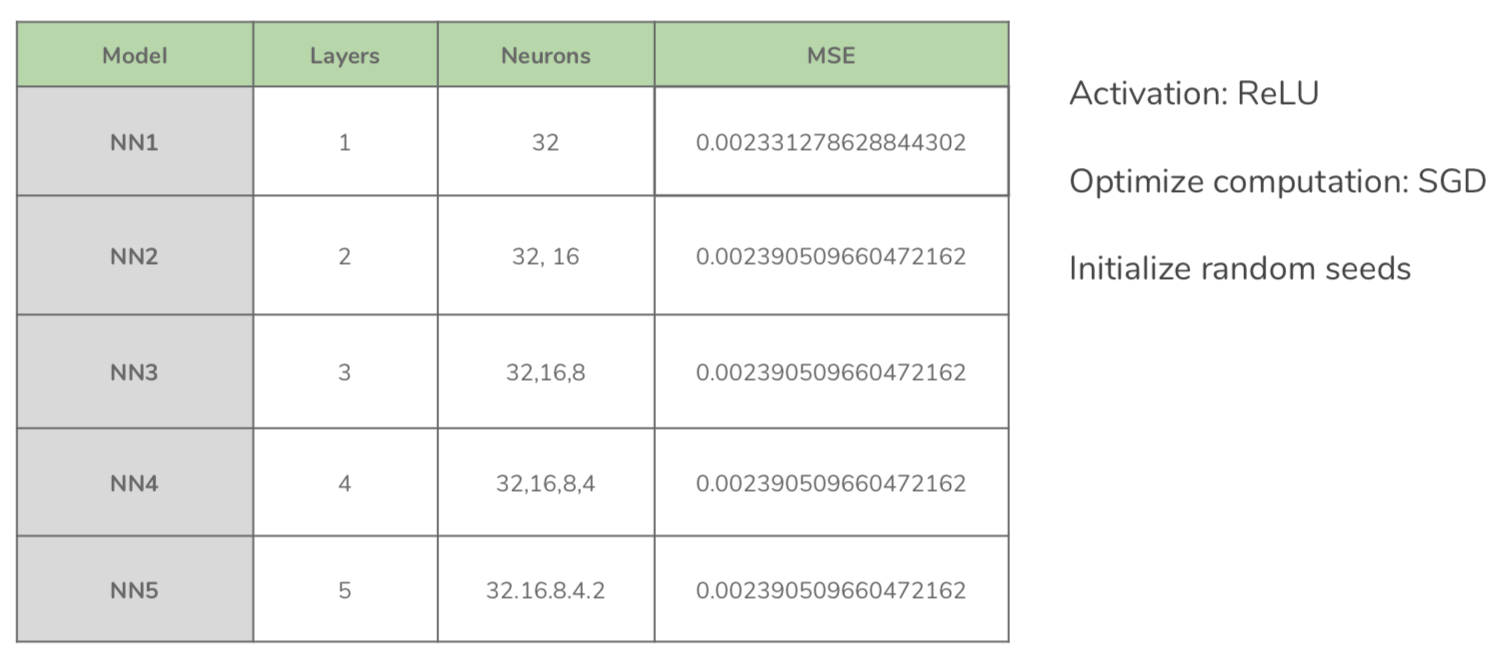
각 모델의 MSE를 보면 NN1의 MSE가 가장 작고 흥미롭게도 NN2부터 NN5까지의 MSE가 동일하다.
6. Conclusion
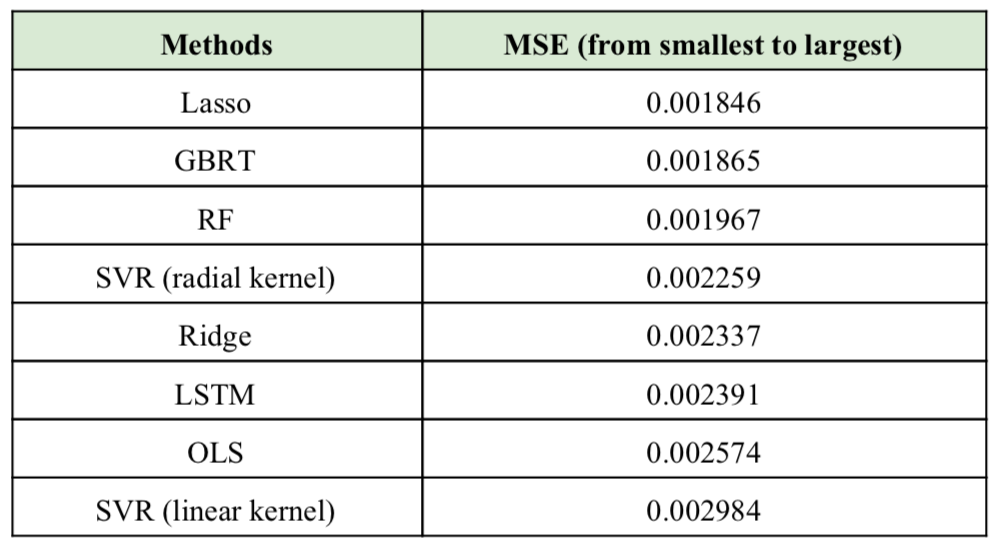
Lasso, GBRT, RF 순으로 예측률이 가장 높았다. 반면, 예측이 가장 낮은 모델은 SVR with linear kernel, LOS, LSTM이었다. 또한 앞서 알아본 feature importance를 종합해보면 가장 자주 언급된 treasury bill rates, stock variance, long term rate of return이 S&P 500 excess return을 예측하는데 있어서 가장 중요한 요소들이라고 할 수 있다.
참고문헌:
Ivo Welch and Amit Goyal (2008). A Comprehensive Look at The Empirical Performance of Equity Premium Prediction.
Shihao Gu & Bryan Kelly & Dacheng Xiu (2018). "Empirical Asset Pricing via Machine Learning, " NBER Working Papers 25398, National Bureau of Economic Research, Inc.